Demystifying the Black Box: A Guide to Interpretable and Explainable AI Models

Hi, I'm Isaac, a multifaceted tech professional with expertise in data analysis, content writing, technical writing, video editing, product management, and customer service.
I enjoy using my diverse skillset to create engaging content and provide helpful solutions for readers and clients. Though my background spans many industries, my passion lies in leveraging technology and creativity to clearly communicate complex topics.
When I'm not writing articles or editing videos, you can find me learning new skills, keeping up with the latest tech trends, and looking for new challenges to tackle.
I'm excited to share my knowledge and continue growing as a professional.
Artificial Intelligence (AI) has made remarkable strides in recent years, transforming different industries and enabling machines to make complex decisions. However, the inner workings of AI models have often been regarded as "black boxes," raising concerns about their transparency and trustworthiness. In this article, we'll unravel the mysteries of black box AI models and introduce you to interpretable and explainable AI techniques. We'll provide some code examples in Python to make the concepts tangible.
Let’s dive in.
Understanding the Black Box
AI models, particularly deep learning models like neural networks, are often perceived as black boxes due to their complex architectures and the opacity of their decision-making processes. These models learn from data, but understanding why they make specific predictions can be challenging.
What is Interpretability and Why Does it Matter?
Interpretability is the ability to understand and explain how a model arrives at a particular prediction. Explainability provides transparency into the reasoning and internal logic behind AI systems. But why does interpretability matter?
Trustworthiness - Users must trust systems to adopt them. Complex models like deep learning can behave as black boxes, making errors mysterious. Explainability builds user trust in model behaviors.
Ethics and Fairness - AI systems must avoid perpetuating historical biases or discrimination. Interpretability allows auditing for fairness. The EU’s GDPR grants users the right to explanations for algorithmic decisions affecting them.
Legal Compliance and Adoption - Regulations increasingly demand explanations of algorithmic systems. The US Federal Trade Commission may soon require explainability for certain AI applications. Interpretability is key for ethical, compliant adoption.
Debugging and Improvement - Insights from interpretable models can reveal and prevent errors, improving performance. Explanations can identify weakly modeled areas needing more training data.
Interpretable AI Models
Let's start by exploring interpretable AI models that are easy to understand and analyze.
Linear Regression
Linear regression is one of the simplest and most interpretable machine learning models. It models a linear relationship between input features and the target variable. Here's a Python code example:
import numpy as np
from sklearn.linear_model import LinearRegression
# Sample data
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
y = np.array([2, 4, 5, 4, 5])
# Create and fit the model
model = LinearRegression()
model.fit(X, y)
# Get coefficients
slope = model.coef_[0]
intercept = model.intercept_
print(f"Slope: {slope}, Intercept: {intercept}")

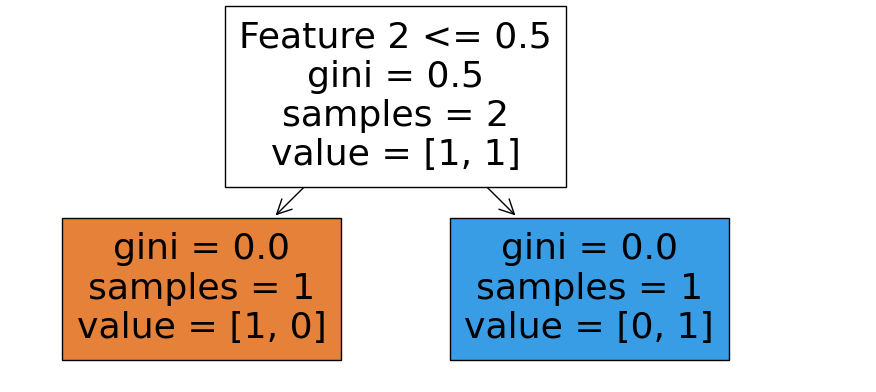
Decision Trees
Decision trees are another interpretable model. They make predictions by following a tree-like structure of decisions. Visualizing a decision tree can help understand its decision-making process:
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# Sample data
X = [[0, 0], [1, 1]]
y = [0, 1]
# Create and fit the model
model = DecisionTreeClassifier()
model.fit(X, y)
# Visualize the decision tree
plt.figure(figsize=(10, 5))
plot_tree(model, filled=True, feature_names=["Feature 1", "Feature 2"])
plt.show()
Explainable AI Models
Now, let's explore explainable AI models that shed light on black box models' predictions.
LIME (Local Interpretable Model-Agnostic Explanations)
LIME is a powerful tool for explaining the predictions of complex models. It works by training a locally interpretable model on a dataset generated around the instance of interest. Here's a Python example:
import lime
import lime.lime_tabular
from sklearn.linear_model import LogisticRegression
import numpy as np
# Sample data for Logistic Regression (2 features)
X_logistic = np.array([[0, 0], [1, 1], [0, 1], [1, 0]])
y_logistic = np.array([0, 1, 1, 0])
# Create and fit the Logistic Regression model
logistic_model = LogisticRegression()
logistic_model.fit(X_logistic, y_logistic)
# Sample data for LIME explanation (2 features)
X_lime = np.array([[0, 0]]) # Replace with your data
# Create a LIME explainer
explainer = lime.lime_tabular.LimeTabularExplainer(X_logistic, mode="classification")
# Explain a specific prediction (e.g., the first data point)
explanation = explainer.explain_instance(X_lime[0], logistic_model.predict_proba)
explanation.show_in_notebook()

SHAP (SHapley Additive exPlanations)
SHAP values are rooted in game theory and provide a unified measure of feature importance for any model. They can be used to explain both global and individual predictions:
import shap
# Create an explainer
explainer = shap.Explainer(model, X)
shap_values = explainer(X)
# Visualize the SHAP values
shap.summary_plot(shap_values, X)
Building Interpretable Neural Networks
Neural networks, despite being black boxes, can be made more interpretable.
Saliency Maps
Saliency maps highlight regions of an input image that influence a neural network's decision. Below is a Python code snippet using TensorFlow/Keras:
import tensorflow as tf
import matplotlib.pyplot as plt
model = tf.keras.applications.MobileNetV2(weights="imagenet")
# Load an image
image = tf.keras.preprocessing.image.load_img("cat.jpg", target_size=(224, 224))
input_image = tf.keras.preprocessing.image.img_to_array(image)
input_image /= 255.0
# Compute the gradients (saliency map)
with tf.GradientTape() as tape:
inputs = tf.convert_to_tensor(input_image[tf.newaxis, ...], dtype=tf.float32)
tape.watch(inputs)
predictions = model(inputs)
top_prediction = tf.argmax(predictions[0])
gradient = tape.gradient(predictions[:, top_prediction], inputs)
gradient = gradient / np.max(np.abs(gradient))
gradient = (gradient + 1) / 2 # shift range from [-1, 1] to [0, 1]
# Plot the saliency map
plt.imshow(gradient[0])
plt.axis('off')
plt.show()

Feature Importance in Neural Networks
You can assess feature importance in neural networks using gradient-based methods or feature occlusion. Here's a code snippet using gradient-based feature importance:
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
def load_dataset():
num_samples = 1000
num_features = 4
X = np.random.rand(num_samples, num_features)
y = np.random.randint(0, 3, size=num_samples)
return X, y
X_train, y_train = load_dataset()
# Convert NumPy array to TF tensor
X_train = tf.convert_to_tensor(X_train)
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(4,)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model.fit(X_train, y_train, epochs=10)
def gradient_feature_importance(model, inputs, class_index):
with tf.GradientTape() as tape:
tape.watch(inputs)
predictions = model(inputs)
loss = predictions[:, class_index]
gradient = tape.gradient(loss, inputs)
feature_importance = tf.reduce_mean(tf.abs(gradient), axis=0)
return feature_importance.numpy()
class_index = 0
feature_importance = gradient_feature_importance(model, X_train, class_index)
plt.bar(range(len(feature_importance)), feature_importance)
plt.xlabel('Feature Index')
plt.ylabel('Feature Importance')
plt.show()


Ethical Considerations
As AI interpretability and explainability are vital, we must also consider ethical aspects:
Fairness and Bias
AI models can inherit biases present in training data. To detect and mitigate bias, you can use libraries like AIF360 or Fairlearn in Python.
Below is a code snippet using AIF360
import pandas as pd
from aif360.datasets import BinaryLabelDataset
from aif360.metrics import BinaryLabelDatasetMetric
from aif360.algorithms.preprocessing import Reweighing
# Create sample biased dataset
data = {'gender': ['male', 'female', 'female', 'male', 'male'],
'hired': [1, 0, 1, 1, 0],
'qualified': [1, 1, 0, 1, 0]}
df = pd.DataFrame(data)
# Encode categorical columns
df['gender'] = df['gender'].map({'male': 0, 'female': 1})
# Convert to BinaryLabelDataset
bl_data = BinaryLabelDataset(df=df,
label_names=['hired'],
protected_attribute_names=['gender'],
favorable_label=1,
unfavorable_label=0)
# Compute original bias metrics
print(BinaryLabelDatasetMetric(bl_data, privileged_groups=[{'gender': 1}], unprivileged_groups=[{'gender': 0}]))
# Mitigate bias using reweighing
RW = Reweighing(unprivileged_groups=[{'gender': 0}], privileged_groups=[{'gender': 1}])
rw_data = RW.fit_transform(bl_data)
# Compute bias metrics after reweighing
print(BinaryLabelDatasetMetric(rw_data, privileged_groups=[{'gender': 1}], unprivileged_groups=[{'gender': 0}]))

Best Practices for Model Interpretability
To ensure model interpretability in practice, follow these best practices:
Model Documentation
Documenting your model is essential for transparency and collaboration. Here are some key components to include in your model documentation:
Model Architecture: Describe the structure of your model, including the type and number of layers, activation functions, and any regularization techniques used.
Hyperparameters: List the hyperparameters used during model training, such as learning rate, batch size, and dropout rate.
Training Data: Specify the dataset used for training, including data sources, preprocessing steps, and any data augmentation techniques applied.
Performance Metrics: Report the evaluation metrics used to assess your model's performance, such as accuracy, precision, recall, and F1-score.
Interpretability Techniques: Document the interpretable techniques employed, such as LIME, SHAP, or saliency maps.
Bias Assessment: If applicable, describe how you assessed and addressed bias in your model.
Results: Provide results and insights gained from model interpretation, including any actionable recommendations.
Model Selection
When choosing a model for your AI application, consider the trade-offs between complexity and interpretability. Here are some guidelines:
Start Simple: If interpretability is a top priority, begin with simpler models like linear regression or decision trees.
Evaluate Trade-offs: Assess the balance between model accuracy and interpretability. Sometimes, a slightly less accurate but more interpretable model is preferred.
Ensemble Models: Ensemble techniques like random forests can provide a compromise between accuracy and interpretability by combining multiple decision trees.
Regularization: Use regularization techniques (e.g., L1 regularization) to promote sparsity in neural networks, making them more interpretable.
The Future Outlook
Explainable AI adoption will likely accelerate due to growing calls for accountability. Techniques to generate explanations must continue evolving beyond simple attention layers or feature attribution methods. The ultimate goal is demystifying even the most complex black box models.
Conclusion
In this guide, we've demystified the black-box nature of AI models by introducing you to interpretable and explainable AI techniques.
Interpretable and explainable AI models are crucial for building trustworthy and ethical AI systems. By following best practices, documenting your models, and being mindful of ethical considerations, you can harness the power of AI while maintaining transparency and accountability.